
Docker is a tool for managing containers and containers, in a nutshell, are packages containing everything a software needs to run, such as system tools, libraries and code. Using Docker, we can quickly deploy and scale applications across multiple environments, ensuring they run the same way even on different machines.
“A container is an isolated environment for your code.” - Docker documentation
In Node JS projects, for example, the Node version as well as the dependencies used in the project will always have the same versions on the team's machines, as well as on production versus staging versus local machines. Another advantage is that we don't need to install Node on our local machine and all project dependencies every time we run the project, they will be managed by Docker through images, containers, volumes and bind mounts.
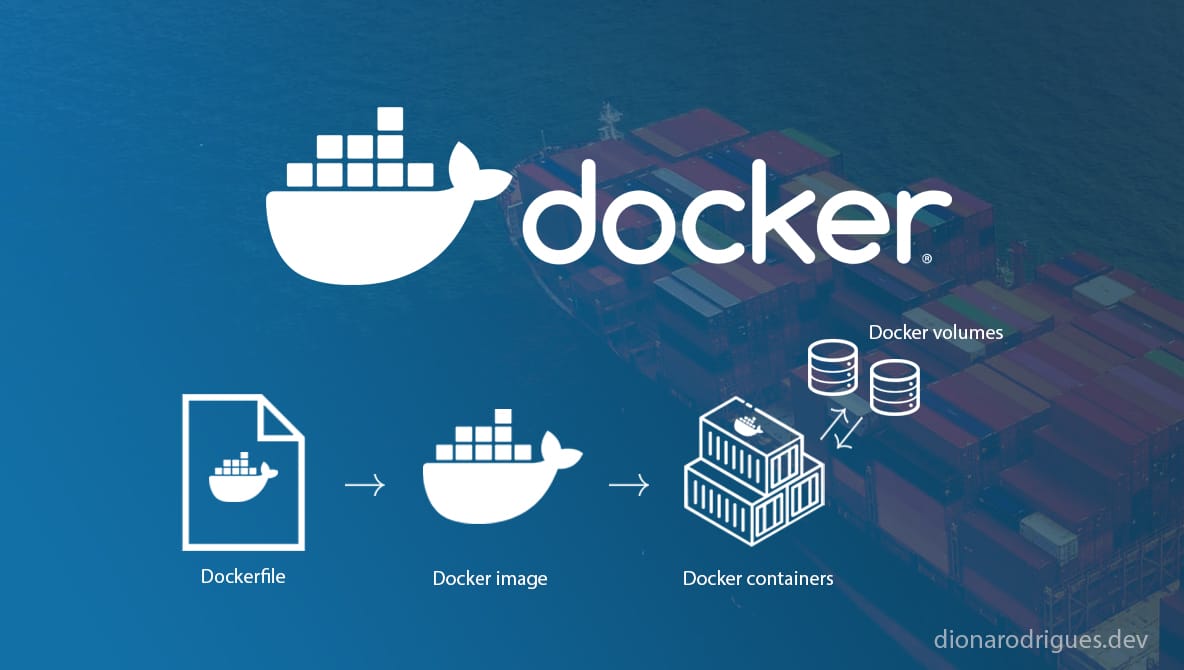
Docker Images, Containers, Volumes and Bind Mounts
- Images: templates / blueprints of code to be executed in a Docker container.
- Containers: they are instances of Docker images, which means they are responsible for running and executing code. Different containers can be created based on the same image, but each of them will have its own data and state.
- Volumes: the mechanism for persisting data outside of containers, fully managed by Docker using a dedicated directory on our host machine (local environment, outside the containers).
- Bind Mounts: is another way to make data stored on our host machine accessible by containers. By using this option we manually bind a file or directory on the host machine to be mounted into a container.
Images can be shared and reused by different containers while containers are created and destroyed over an application’s lifecycle.
Once an image is built, it creates a snapshot of the code and lock it. So, in case we need to update the code inside a container a new image should be created to be used by the containers attached to it. Of course there are other ways to make it flexible using volumes and bind mounts.
Last but not least, data can be managed using volumes and bind mounts, and there are different ways to do this, but I will explain later.
Docker commands reference
This is a brief reference to some commands that you will see in the next sections.
Main commands
docker build [path_of_the_dockerfile](or just . (dot) if it’s running from the same directory): creates an image based on dockerfile instructionsdocker run -p [host_port]:[container_port] [imge_id/name]: creates a container based on the image and enable a local port to access the projectdocker —help: we can use it along with any docker command to see a list of related commands and their explanations
Docker image commands
docker images: list all imagesdocker rmi [image_id/name]: delete the imagedocker image prune: delete all unused imagesdocker image prune -a: delete all imagesdocker inspect [image_id/name]: display info about the image
Docker container commands
docker ps: shows all containers that are runningdocker ps -a: shows all created containersdocker stop [container_id/name]: stops the containerdocker start [container_id/name]: starts an existing containerdocker logs [container_id/name]: display all the logs of that container in the terminaldocker rm [container_id/name]: delete the container
Docker volume commands
docker volume ls: lists all volumesdocker volume rm [volume_name]: deletes volumedocker volume prune: removes all unused volumes
What's Dockerfile
Dockerfile is the name of the file - usually created in the root project directory - to handle the instructions to create an image for our project (we can also specify other images we are going to use to compose our own image, like Node image, as well as some instructions to copy files, install dependencies…).
As you see, images can be shared and the main tool to manage it is the Docker hub.
Example of Dockerfile
Note: The code below is based on a Node application and will be used through this article as an example for most of the commands in the next sections.
Let's imagine that we have an application containing a file called server.js that is responsible for this Node application and exposes it on port 80.
// Build this image based on node image
FROM node
// The working directory (is created if it doesn't already exist)
WORKDIR /app
// Copy package.json into /app folder
COPY package.json /app
// Install all dependencies
RUN npm install
// Copy all directories and files from the root into /app folder
COPY . .
// Expose the Node application port
EXPOSE 80
// Run default commands when a container is started
CMD ["node", "server.js"]See all supported instructions by Dockerfile in the Docker documentation.
Difference between RUN and CMD:
RUNexecutes the instruction when the image is createdCMDexecutes the instruction when the container is started
Docker image layers
When an image is rebuilt, Docker is smart enough to recognise what have been changed and then use the cached result of the instructions instead execute every instruction again and again, which is great for optimisation. It’s called layer based architecture, where each instruction represents a layer that is cached.
Once a layer is changed (i.e. the result of an instruction), Docker runs that layer and the next ones again instead of getting them from the cache, which is why we first copy package.json and install its dependencies in the example above before copying all other files. By doing this, we guarantee that dependencies will only be reinstalled when package.json is changed. If we add package.json after copying the other files, any small changes to these other files will install all Node dependencies again.
Container is just another layer on top of it. So, because one image can have multiple containers, each one of them is a separated layer on top of the Dockerfile instructions.
How to create images and containers
The examples below are based on the Dockerfile of the section above, in a scenario where the Dockerfile is located in the root of the project and we are executing the Docker commands in the same directory level of this file.
Creating Docker images
docker build .
Once the command above is run, and an image is created based on the Dockerfile, we can copy its generated id to be used to run the container. In case you need to check the image id after its creation, you can use docker images to list all of them.
Creating Docker containers
docker run -p 3000:80 -d --rm sha256:65597563a5b3d5b5b74dcc5e27256f015f8fc7a57f5adfc79e7c4517a156dcfd
Here we have:
- the id of the image (the long hash at the end of the command - I’ll show how to manage images using custom names later)
-p 3000:80is used to enable a local port to access the project port from the Docker container-dto run the container in background, so the terminal will be free to run other commands--rmto delete the container as soon as it is stopped
A more basic command would be:
docker run -p 3000:80 sha256:65597563a5b3d5b5b74dcc5e27256f015f8fc7a57f5adfc79e7c4517a156dcfd
Once a container is running, you can stop it. So you can list all the containers using docker ps to list all the containers that are running, get the ID of the container you want to stop, and then run docker stop 0401f0d42e86, where the hash in this example is the container ID.
Naming images and containers
Naming Docker images
docker build -t [image_name]
docker build -t [image_name]:[tag_name] .
We can use tags (-t) to specify not only the image name but also its different versions, like node:14, for example ("node" is the image name and "14" is the version of this image).
Example:
docker build -t sunflower .
docker build -t sunflower:latest .
These commands create an image called “sunflower” and also a version of it called “latest” (which can be numbers or any other word you want).
Renaming Docker images
docker tag [current_image_name]:[current_tag_name] [new_image_name]:[new_tag_name]
docker tag sunflower:latest butterfly:latest
This command will replace the image name “sunflower” to “butterfly”.
Naming Docker containers
docker run -p 3000:80 -d —rm —name [container_name] [image_name/id]
Example:
docker run -p 3000:80 -d --rm —name myapp sunflower
This command will create a container called “myapp” based on an image called “sunflower”.
Sharing images
There are two ways to share an image: sharing the Dockerfile or pushing the image to Docker hub by making it disposable in private or public repository.
Bellow you can check out some steps to push a local image onto Docker hub.
- Go to Docker hub
- Login and access your repositories, and create a new one
- Your remote repository should match with your local image name.
- Use
docker push [image_name]to push your image to Docker hub
Example:
docker push dionarodrigues/butterfly:latest
Where "dionarodrigues" is my username in Docker hub and "/butterfly:latest" is the repository name. So, my local image should be called "dionarodrigues/butterfly:latest"
And this is the command to use an existing image from Docker hub:
docker pull [repository/image_name]
Example: docker pull node or docker pull dionarodrigues/butterfly:latest
Managing data with Docker
Basically, there are 3 ways to manage data inside docker:
- Images: when we create an image and copy the code into it from Dockerfile by using the command
COPY. Data will be locked, read-only, until the image is created again. So, even if we change the files we copied into the image, they will just be updated with the latest changes when the image is rebuilt again as they are a snapshot from the time the image was created. - Containers: the data is stored when a container is running and destroyed when a container is deleted. The difference here is that we can manage files while the container is running, however it’s not easier as the data will be in memory. For example, we can have a form that will create a file when submitted which will be available to be accessed while its container is running. Don’t forget that it will be deleted along with the container.
- Volumes: are files and folders on our host machine (local environment, outside the containers) controlled by Docker that are mapped with folders inside the containers. Docker volumes can persist data even when containers are deleted. Let's take the same example of the file being created by a form submission: when this file is stored on a volume, it can be shared with other containers and will persist even after the container that generated that file is deleted.
- Bind Mounts: Similar to volumes, where data persists independently of containers, but with Docker bind mount we control where files and directories to be mounted in containers are stored on our host machine and any changes made to this mapped data will be instantly reflected in the container while with volumes no. So this is the solution to be able to easily create/edit/delete files inside a container even if it is running. Imagine you have started a React application using Docker and you are editing the JSX files and these files are mapped into the container using bind mount so that you see the changes reflected in the interface as soon as you save the file changes, no need to build a new image for that.
Volumes
As you saw in the section before, volumes are folders in our host machines, managed by Docker to persist data by mapping local with container folders.
You can find a full example of how to create volumes in the next section called "How to create volumes and bind mounts", before let’s dive into the 2 ways to create them:
Anonymous volumes
This kind of volume is attached to the container, so it will only be useful while the container exists, however it survives when the container stops to run. It can’t be shared across different containers.
It’s useful when you need to keep a file inside the container untouched while you replace other files there, for example.
To create anonymous volumes, we can add an instruction in the dockerfile:
VOLUME [“/app/node_modules”]
Or run the command below along with the container command:
-v [folder_inside_container_to_be_persisted]
Example:
-v /app/node_modules
Named volumes
By assigning a name to the volume during the container creation, this data can be persisted after the container is deleted and can also be shared across different containers.
Once we name the volume, Docker will check if it already exists, and if yes, Docker will use it instead of creating a new one.
A good example is when a container is running and a form is submitted and the application creates a file containing the form data and stores it in a folder called “/app/feedback”. So to keep this data (file) even after the container is deleted, we can use a named volume by passing the path of this file folder along with the name of the volume. Then this data can be used to start this container again or even when creating another container.
To create named volume we run the command below along with the container command:
-v [volume_name]:[folder_inside_container_to_be_persisted]
Example:
-v feedback:/app/feedback
Bind Mounts
Different of the other options, where Docker controls where the data is stored, now we have full control of it. With Docker Bind Mounts we map folders from our local environment with folder inside containers, which is amazing as now we can create/edit/delete files and see the changes instantly reflected in the container. By using this option the data will be persisted even after container deletion as the data will be in our host machine.
For example, let's say you are working on a React project and want to use docker to start your project. With Docker bind mounts, you can map your project's folders and files with those inside the Docker container, so you can create/edit/delete any file or directory and see the changes in your browser instantly. That said, the container will use your local files, not those locked when the image was created or those created inside the container or those created Docker using volumes.
To create bind mounts we run the command below along with the container command:
-v [full_path_of_our_machine_folder]:[folder_inside_container_to_be_maped_with_our_machine_folder]
Example:
-v /Users/dionarodrigues/Documents/Development/my-project:/app
Just a quick note: If you don't always want to use the full path, you can use these shortcuts:
- MacOS / Linux:
-v $(pwd):/app - Windows:
-v "%cd%":/app
Example:
-v $(pwd):/app
How to create volumes and bind mounts
Although we have 3 different options (anonymous and named volumes and bind mounts), we can combine them to make sure all the data will be persisted when a container is created. Bellow is an example using all of them together:
docker run -d -p 3000:80 --rm --name [container_name] -v [folder_inside_container_to_be_persisted] -v [volume_name]:[folder_inside_container_to_be_persisted] -v [full_path_of_our_machine_folder]:[folder_inside_container_to_be_maped_with_our_machine_folder] [image_name/id]
docker run -d -p 3000:80 --rm --name myApp -v /app/node_modules -v feedback:/app/feedback -v "/Users/dionarodrigues/Documents/Development/my-project:/app" sunflower
Or using shortcuts for the local machine path:
docker run -d -p 3000:80 --rm --name myApp -v /app/node_modules -v feedback:/app/feedback -v $(pwd):/app sunflower:latest
In this example we use anonymous volume (first -v in the example) to prevent “node_modules” to be overwritten when we map all folders of our local machine with folders inside the container (bind mounts, third -v). Named volume (second -v) is used here as an example to persiste data created inside the container when it’s running, so that we can share this data with other containers or even initialise a container with this data (if it already exists).
Like images and containers, you can manage volumes by listing them using docker volume ls command to get their names and them delete them using docker volume rm [volume_name] command or even deleting all unused volumes with docker volume prune command.
Conclusion
The main concept in Docker is containers. Containers are completely isolated processes from our machines having all they need to run our projects code. Each container is independent and can be portable to anywhere, what means that the same container will run on the same way in local and production environments, for example, guaranteeing the same version of dependencies and the database.
Docker containers are created based on Docker images (packages containing all files and configurations to run a container), which are created using instructions from Dockerfile.
Data can be persisted using Docker Volumes and Docker Bind Mounts. While Docker controls where data on our host machine is stored, we control it using bind mounts, and the latest is the solution to manage file changes and have them instantly reflected in the container, good when we are running React application using Docker, for example, and editing JSX files.
I hope you have learned a lot from this article. See you next time! 😁